
 There are those who say that the Isle of Wight is one big Departure Lounge in the sea, an Island of Biddies and Gilberts waiting for their Final Flight. As it happens, Dr No knows the Island well. It certainly has more than its fair share of Departure Lounges, but it is also a very beautiful Island. Dr No has spent many a happy day savouring its special blend of peace and tranquillity.
There are those who say that the Isle of Wight is one big Departure Lounge in the sea, an Island of Biddies and Gilberts waiting for their Final Flight. As it happens, Dr No knows the Island well. It certainly has more than its fair share of Departure Lounges, but it is also a very beautiful Island. Dr No has spent many a happy day savouring its special blend of peace and tranquillity.
Some time ago, Rita Pal, fancying herself a cushy number, took up a medical SHO post at the Island’s main hospital. Needless to say, all those Biddies and Gilberts meant not less but more medical work. She uses the occasion to remind us that not all GPs are paragons of virtue. Some are dreadful. She tells a gruesome tale of not four but five Horsemen of the Apocalypse, masquerading as GPs, who helped one Island Gilbert on his way.
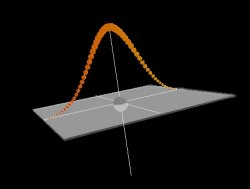
Dr No agrees with Dr Pal. GPs vary greatly in their competence. Some are almost too good to be true; others eye-wateringly bad. Most are probably somewhere in the middle. In fact, if there were available some global measure of medical competence, it is more than likely that that measure would be Normally distributed amongst doctors, including GPs. It is a feature of a Normal distribution that just under half the scores will be lower – and so in this case, worse – than average. Which means an awful lot of GPs are worse than average. Sure, some will be imperceptibly worse, but others will be more so, and a smaller number will be dreadful.
Now, the GMC, in its Revalidation propaganda, regularly assures us that, for the great majority of doctors, revalidation, and the underpinning appraisal, will be a breeze, because the great majority of doctors already practise to a high standard. The are saying, in effect, that instead of being Normally distributed, medical competence follows some bizarre skewed, or even bi-modal distribution.
This is the sort of nonsense dreamt up by cross-eyed apparatchiks. If, as Dr No has suggested (and there is no reason to suppose it is not), medical competence is Normally distributed, and so nearly half of all doctors are of below average competence, then it cannot for a moment be the case that the “great majority” of doctors are at a “high standard” – unless, that is, that “high” here, in some Orwellian twist, means not high, as opposed to low, but some elastic and arbitrary “standard” also dreamt up by this bunch of cross-eyed apparatchiks.
Or – to put it another way, it is a bit like asking folk about their driving skills. Most will say they are better than average. But, if you think about it, it just doesn’t add up…
Dr No has no way of knowing whether the GMC is just plain thick, and cannot see the absurdity of its proposed wonky distribution of medical competence, or whether in fact it has spotted it, but has decided instead to issue calming but deceiving platitudes to the effect that, for the great majority, all will be well.
Whatever the GMC’s motives, when the time comes, it will find itself caught between the devil and the deep blue sea. Set the cut-off point low, and many many Horsemen of the Apocalypse will continue to ride out; set it high, and there will be a massive cull of practising doctors. Either way, it will be medical Armageddon.